 Skip to content
Skip to content 
Multi-Agent Reinforcement Learning for Shepherding
PyTorch | Machine Learning | Stable Baselines 3 | Python | PPO | SAC
Project Overview
For this project, I developed a multi-agent reinforcement learning framework to address a complex shepherding task in a simulated environment. The problem involves coordinating a team of robotic shepherds to guide a group of sheep-like agents toward a designated goal, emulating real-world shepherding dynamics.
The foundation of the project is a custom-built simulation environment where both shepherds and sheep are modeled as differential-drive robots. The sheep behavior is derived from the Strombom model, a biologically inspired approach to sheep-flocking dynamics. Reinforcement Learning agents are trained using algorithms such as Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC), to explore effective strategies for controlling the shepherd robots under dynamic and uncertain conditions.
Learning intelligent shepherding strategies for locally interacting agents using Multi-Agent Reinforcement Learning.
Problem Statement and Objective
The herding task centers on coordinating a group of robotic agents, known as shepherds (or sheepdogs), to guide another group of agents, modeled as sheep, toward a predefined goal region in a 2D simulation environment. Both the shepherds and sheep are modeled as differential-drive robots, introducing constraints on their movement and control strategies.
Key challenges include:
- Multi-Agent Coordination: Shepherds must cooperate to efficiently herd sheep without scattering them or deviating from the target trajectory.
- Dynamic Flock Behavior: Sheep behavior is driven by the Strombom model, causing them to predictably respond to the actions of the shepherds.
- Scalability: As the number of agents increases, the complexity of interactions grows, making it harder for a reinforcement learning policy to generalize.
The objective is to train a reinforcement learning agent capable of solving these progressively complex tasks and discover/improve upon the Strombom heuristics while maintaining adaptability, scalability, and efficiency.
Strombom Model
Sheep Behavior:
- Avoidance: Sheep instinctively move away from the shepherd when it comes within a certain proximity, responding to the perceived threat.
- Cohesion: To maintain flock integrity, sheep move toward other nearby sheep, preserving the herd structure.
Shepherd Behavior:
- Herding: By positioning itself strategically, the shepherd herds the sheep into a cohesive group using indirect pressure.
- Positioning: The shepherd calculates an optimal position behind the herd, relative to the goal, to influence the sheep’s movement effectively.
The Strombom model relies on localized, heuristics-based behaviors for each agent. While individual actions are simple, collective interactions result in effective and coordinated herding, showcasing the power of emergent behaviors.
Shepherd herds the Sheep to the Goal region using the Strombom heuristics, the blue dot without the center mark represents the target point for the shepherd.
Drawbacks of the Strombom Model
While the Strombom model demonstrates the effectiveness of simple rule-based herding behaviors, it has several significant limitations that restrict its practical applicability:
- Over-Reliance on Handcrafted Heuristics: Heavily dependent on predefined rules, limiting adaptability to new scenarios.
- Limited Robustness to Initial Conditions: Requires specific initial positions, failing with random placements.
- Inefficient Movement: Redundant movements result in increased completion times, a product of rigid movement rules.
For this project, I use the Strombom Sheep Model to guide the reactive behavior of the sheep while a trained RL agent controls the movements of the shepherds.
Custom Simulation Environment
The simulation environment for the herding task is custom-built to provide flexibility, realism, and compatibility with reinforcement learning (RL) libraries like Stable-Baselines3. Below is an overview of its key features:
- Visualization Using Pygame: The simulation leverages Pygame for visualizing agent interactions in a 2D arena. This allows real-time tracking of the herding task with clear, animated representations of sheep, shepherds, and the goal region.
- Differential Drive Robot Modeling: All agents, including sheep and shepherds, are modeled as differential drive robots. This enables realistic movement dynamics where the agents can turn and move based on independent wheel velocities, accurately simulating real-world robotic constraints, and ensuring that solutions developed in simulation can generalize to real-world scenarios.
- Control Modes: The simulation provides three distinct control modes for shepherds:
- Wheel Mode: Directly control the left and right wheel velocities, offering granular control over the robot’s movement.
- Vector Mode: Specify a heading vector and speed for shepherds, simplifying control while still adhering to the physics of differential drive systems.
- Point Mode: Specify a destination point on the map, and the simulation calculates appropriate wheel velocities to navigate the shepherd toward the target, abstracting low-level control.
- Sheep Behavior: Sheep are modeled based on the Strombom model heuristics, which dictate their reactive behavior. They avoid shepherds, flock together for cohesion, and move in response to shepherds’ actions.
- Multi-Agent Coordination: The environment supports interaction among an arbitrary number of agents, including multiple shepherds and sheep. This feature allows testing and training strategies for complex multi-agent scenarios.
- Gymnasium Integration: The environment is designed to wrap seamlessly into a Gymnasium-compatible framework, enabling integration with RL libraries like Stable-Baselines3. This compatibility facilitates the training of RL agents using popular algorithms such as PPO and SAC.
Custom simulation environment showing a single Shepherd (manually controlled) herding ten Sheep (behavior modeled on Strombom heuristics)
Reinforcement Learning Framework: Stable-Baselines3
Stable-Baselines3 (SB3) is a widely-used Python library for implementing and training reinforcement learning (RL) agents. Built on top of PyTorch, it provides a collection of state-of-the-art RL algorithms such as PPO, SAC, DQN, and more.
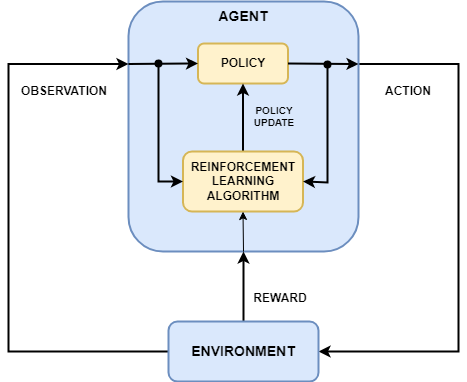
In a typical Stable-Baselines3 training environment, the process begins with initializing and resetting the environment, setting up agents and goals. At each timestep, the agent selects an action based on its policy, which the environment processes to update the state. A reward signal is then calculated to reflect performance, incentivizing desired behaviors and discouraging suboptimal ones. After collecting a batch of experiences, the RL algorithm updates the agent’s policy or value function, gradually improving decision-making. Episodes terminate upon reaching goals or exceeding maximum steps, and the environment resets for the next run. Throughout training, metrics like rewards and losses are logged, enabling detailed monitoring via tools like TensorBoard and WeightsAndBiases.
I utilized the SB3 implementations of Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) algorithms to train the agent for this project.
Proximal Policy Optimization (PPO)
PPO is a popular reinforcement learning algorithm designed for policy optimization with improved stability and performance. It operates by updating the policy through gradient ascent while enforcing constraints to prevent overly large updates that destabilize learning. This is achieved using a clipped objective function, which ensures changes to the policy remain within a predefined range. PPO effectively balances exploration and exploitation, supports continuous and discrete action spaces, and is highly scalable, making it well-suited for environments requiring robust, stable learning.
Soft Actor-Critic (SAC)
SAC is an off-policy reinforcement learning algorithm tailored for continuous action spaces, focusing on efficient exploration and stability. It uses an entropy-augmented objective, encouraging policies that explore uncertain areas of the state space while prioritizing actions that maximize expected rewards. By maintaining separate networks for the actor (policy) and critic (value function), SAC ensures robust updates and reduces training instability. Its ability to handle complex environments with high-dimensional action spaces makes SAC a powerful choice for challenging control tasks.
Reward Function Design
The reward function for the shepherding task incentivizes efficient, goal-oriented behavior while penalizing inefficiency. A large reward is given for successfully herding the sheep into the goal region, while a small time penalty encourages rapid convergence. The reward structure also includes intermediate incentives for minimizing the sheep’s distance from the goal and reaching the goal region. Negative rewards are applied if the score (based on sheep distances) worsens, ensuring agents prioritize improvements. These elements collectively guide the reinforcement learning agent toward achieving the herding task effectively within the constraints of the environment.
Vectorized Environments
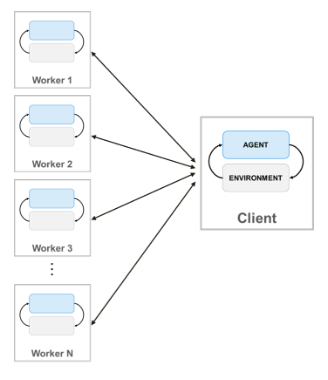
Training for the herding task leverages vectorized environments to enhance sample efficiency and accelerate learning. By running multiple instances of the environment in parallel, the reinforcement learning agent collects diverse experiences across varied scenarios within each training step. This approach ensures that the agent encounters a wide range of initial positions and configurations of sheep and shepherds, improving its generalization capabilities. Stable-Baselines3 supports this kind of a setup, enabling efficient data collection and model updates. The parallelized training setup significantly reduces the overall training time while ensuring robust policy development for complex multi-agent tasks such as this one.
Results
The training process demonstrates the effectiveness of reinforcement learning in solving the single sheep, single shepherd herding task using the point control mode in a continuous action space. Over 20 million timesteps, the agent learns an optimal policy, consistently achieving the task of guiding sheep from random initial positions to random goal positions. The training metrics, including mean episode rewards and episode times, show steady improvement, highlighting the convergence of the policy.
Simulations (left to right) show the training progress of the RL agent
At first, the agent executes random actions. It then learns to approach the sheep and interact with it. Over time, it learns to push the sheep around the arena.
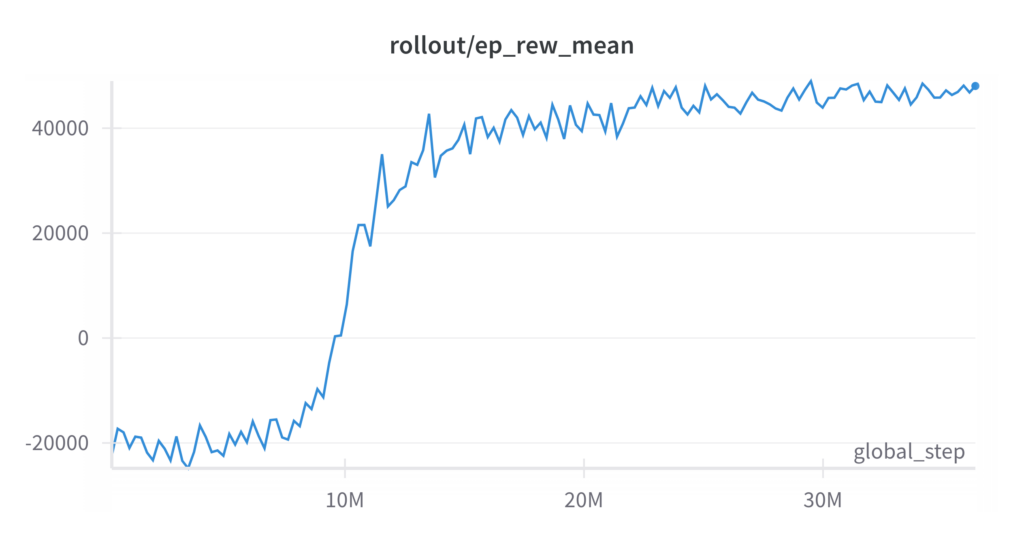
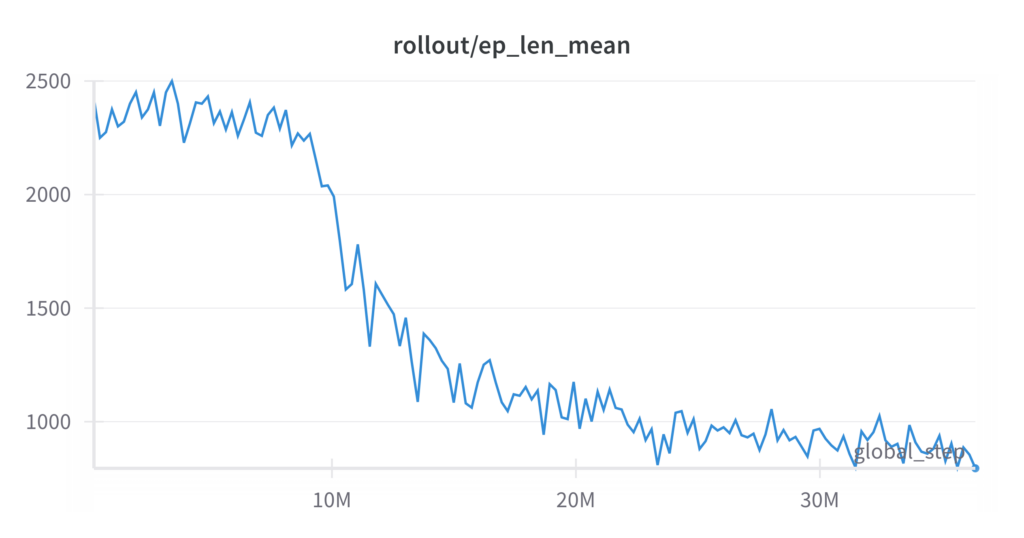
Training metrics, Left: Mean Reward per episode; Right: Mean Length per episode
Reinforcement Learning Agent trained to herd a single sheep using Proximal Policy Optimization (PPO)
In contrast, attempts to train agents directly on multi-sheep, multi-shepherd setups exhibit significant challenges. Training curves for these setups show erratic behavior and lack convergence, reflecting the increased complexity of the problem. The inherent difficulties in coordinating multiple agents and the high-dimensional interactions exceed the capability of standard reinforcement learning approaches, suggesting that additional strategies or problem simplifications are necessary for scalable solutions in these cases.
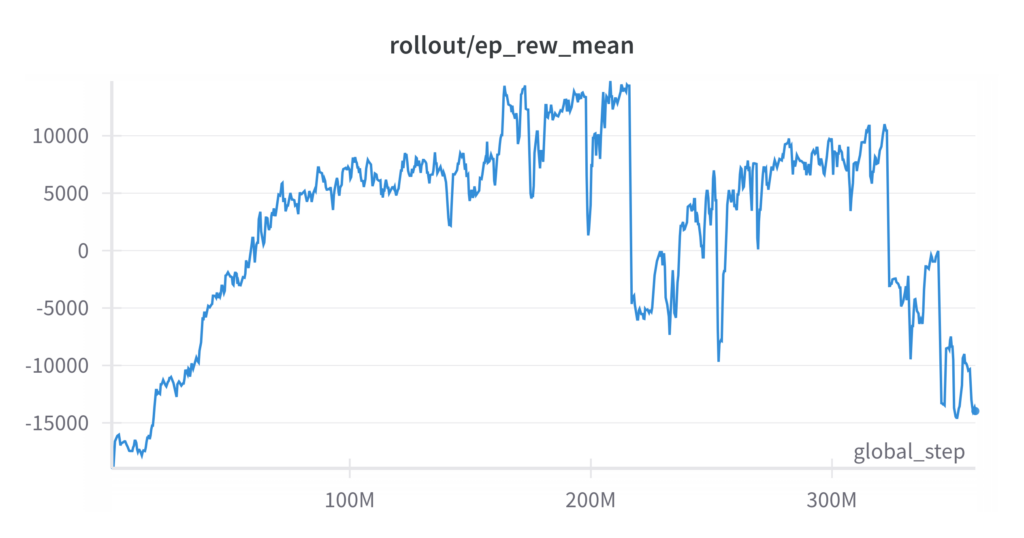
Training metrics for multi-sheep/multi-shepherd setup, Left: Mean Reward per episode; Right: Mean Length per episode
RL agent fails to effectively control multiple-shepherds simultaneously to herd multiple sheep
Multi-Agent Generalization
To address the challenges of coordinating multiple agents, I implemented an attention-switching strategy that extends the single shepherd-single sheep model to scenarios with multiple agents. Each shepherd in the scene is dynamically assigned to a sheep based on proximity and priority. Specifically, each shepherd focuses on the sheep closest to it but farthest from the goal, ensuring that every sheep receives targeted attention. This way, a model that is trained on a single shepherd-single sheep model is scaled to handle multiple agents in the environment.
Each Shepherd dynamically targets one Sheep farthest from the goal, sheep marked in Red are being targetted for herding
This strategy generalizes to any number of agents by maintaining independent decision-making for each shepherd while adhering to the overarching herding objective. The simplicity of this approach allows efficient herding behaviors to emerge as the shepherds collectively guide the sheep toward the goal region. By leveraging this framework, I achieved successful herding across varying configurations, showcasing robust scalability and adaptability in complex multi-agent scenarios.
Shepherd – 2 Sheep – 5
Shepherd – 3 Sheep – 10
Shepherd – 5 Sheep – 20
Future Work
Future work on this project could focus on scaling the system to larger environments with more complex dynamics, enabling more realistic simulations. A centralized multi-agent solution could also be explored, where a single controller coordinates the actions of all agents, improving coordination across the scene. Additionally, experimenting with alternative multi-agent reinforcement learning algorithms, such as value decomposition or attention-based models, could enhance performance and adaptability in more challenging scenarios. Beyond the herding task, the approach could be applied to various domains, such as search-and-rescue missions, where collaborative robot behavior is essential, or smart collective motion strategies for autonomous vehicle fleets.
