 Skip to content
Skip to content 
Franka plays Hangman
ROS2 | Python | Computer Vision | Motion Planning | Inverse Kinematics | OpenCV | MoveIt2 | OCR
Project Overview
The goal of our project was to use the Franka robot as a facilitator for a game of hangman. Our robot is able to setup a game of hangman (draw the dashes and hangman stand) as well as interact with the player (take word or letter guesses) before writing the player’s guesses on the board or adding to the hangman drawing.
In order to accomplish our project’s core goals, we developed: a force control system combined with the use of april tags to regulate the pen’s distance from the board, an OCR system to gather and use information from the human player, and a hangman system to mediate the entire game.
Team Members: Abhishek Sankar, Ananaya Agarwal, Graham Clifford, Ishani Narwankar, Srikanth Schelbert
Gameplay Demonstration
How to play Hangman?
The object of hangman is to guess the secret word before the stick figure is hung. Players take turns selecting letters to narrow the word down.
Generally, the game ends once the word is guessed, or if the stick figure is complete — signifying that all guesses have been used.
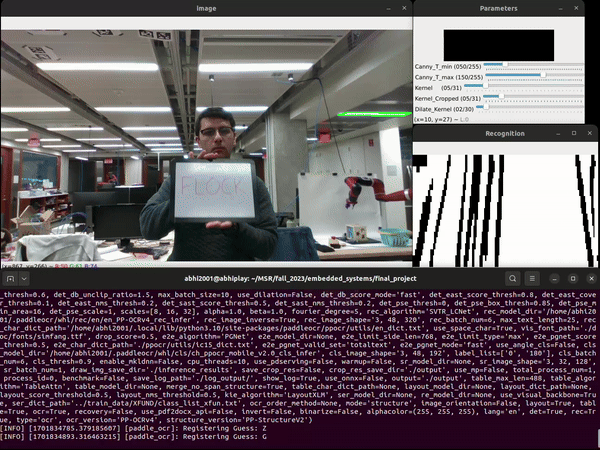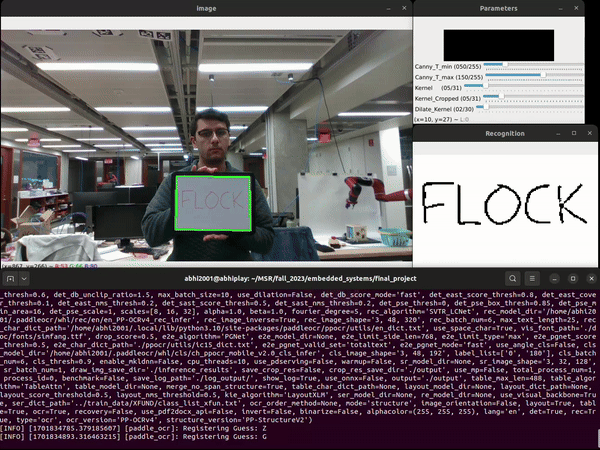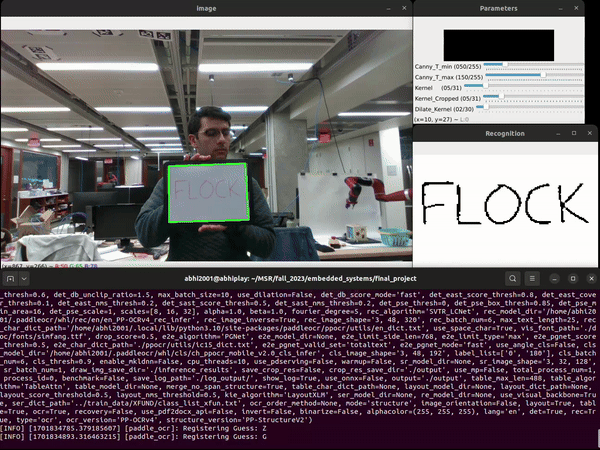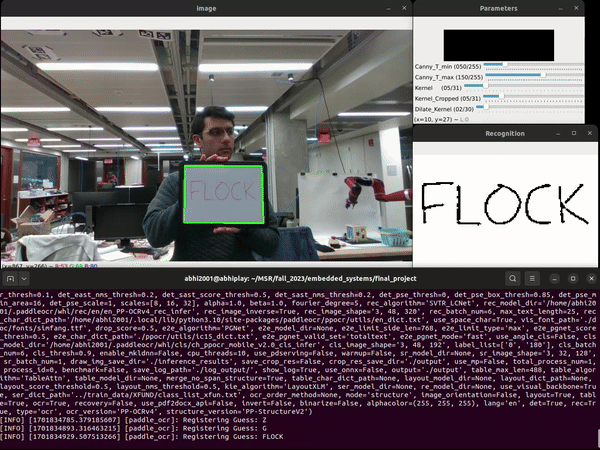
Computer Vision and Optical Character Recognition
The player writes down the guess on a handheld whitboard and holds it up to the camera mounted on the end-effector of the Franka robot arm. We use the PaddleOCR toolkit to identify the text in the image obtained from the camera. The Paddle OCR toolkit includes a number of pre-trained deep learning models that have been trained on a variety of datasets to recognize and extract text from various types of images and documents.The PaddleOCR model comprises two layers: text detection and recognition. The detection layer searches for text in the image, identifying regions of interest, while the recognition layer identifies the text within these bounded regions, providing predictions with associated confidence values. Our tests indicate that the model struggles to reliably detect single characters in images, seemingly because it is trained on materials such as books and articles that feature large blocks of text. Consequently, it fails to produce accurate guesses in such scenarios. To address this issue, we disable the text detection feature in PaddleOCR and exclusively utilize its text recognition capability.
We use OpenCV to modify the image before feeding it into PaddleOCR in order to improve accuracy:
- Convert the image from RGB to grayscale.
- Apply Gaussian blurring to reduce noise.
- Employ Canny edge detection to identify edges in the image.
- Identify closed contours and sort them based on contour area.
- Iterate over the contours to pinpoint the largest contour approximating a rectangle, which corresponds to the whiteboard.
- Apply a four-point perspective transform to straighten the image.
- Binarize the warped image using adaptive thresholding to account for lighting differences.
- Use the dilation operation to widen the text within the bounded region (only performed for single-character recognition).
The OCR model provides predictions with associated confidence values. To refine result accuracy, we’ve implemented a simple filtering mechanism. This filter assesses predictions from the OCR model, gauging their legitimacy based on both the frequency of a particular prediction and its confidence value. High-confidence guesses pass through quickly, while low-confidence and frequently occurring predictions may experience a slight delay but are eventually processed. However, low confidence and infrequent predictions are prevented from passing through altogether. This approach ensures that our system avoids false-positive predictions, maintaining a more reliable and accurate output.
Admittance Control (Force + Position)
Our admittance control system works as follows: Calculate the expected torque in panda_joint6 due to the weight of the gripper and its attachments. Obtain a plane from the april tag attached to the whiteboard. The robot will attempt to draw at points in this plane. Subtract this expected torque from the actual torque in panda_joint6, and then convert any difference in these two values into linear force in the end-effector’s frame. If we measure a force greater than a certain threshold in the end-effector frame’s x direction, then we must be making contact with the whiteboard. At this point, stop moving the gripper. We learned that apparently we cannot cancel action goals in ROS Iron at this time. Because of this, we had to write our own node for executing planned robot trajectories. This node works as follows: Plan a trajectory, and then repackage that trajectory into a list of JointTrajectory messages, each with one JointTrajectoryPoint. Change the time_from_start parameter in the JointTrajectoryPoint message to 100000000 nano seconds. If you do not do this, the robot will behave unpredictably. Publish each of these JointTrajectory messages one by one on the /panda_arm_controller/joint_trajectory topic in a timer_callback with a 10hz frequency. After stopping the gripper, update the plane obtained from the april tag at the beginning of the procedure to be aligned with the point the end effector impacted the whiteboard. Plan a trajectory to the next pose in the queue. Move to this point with PID admittance control enabled, where the input to the PID loop is the force at the end effector, and the output is the angle of panda_joint6.This method is inaccurate, and a little crude. The calculation of the force at the end-effector isn’t always correct, joint torque measurements from the franka itself can be noisy and erratic, and using only the angle of panda_joint6 as the output of the PID loop can cause curved lines drawn on the whiteboard. In the future, a better implementation would be to write a c++ node that completely controls the franka, alongside a ros_control c++ file that implements the admittance control. I’m not sure if both or only one of these would be necessary. Libfranka does a lot more math for you than MoveIT does which is essential for admittance control.
